
Multitask-Learning Paper Overview 1
An Overview of Multi-Task Learning in Deep Neural Networks
Reference: Ruder S “An Overview of Multi-Task Learning in Deep Neural Networks”, arXiv:1706.05098, Hune 2017
MTL in Deep Neural Net:
Sharing types:
- Hard Sharing
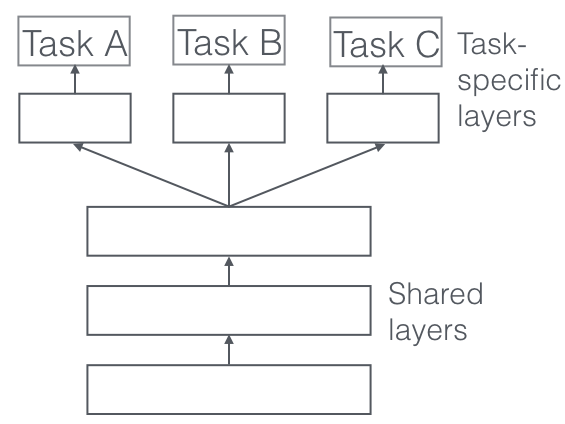
Hard sharing is most commonly used in MTL, especially in MTL+neural nets. This is applied by sharing hidden layers between all tasks, to lower the risk of overfitting.
“The more tasks we are learning simultaneously, the more our model has to find a representation that captures all of the tasks and the less is our chance of overfitting on our original task.”
- Soft Sharing
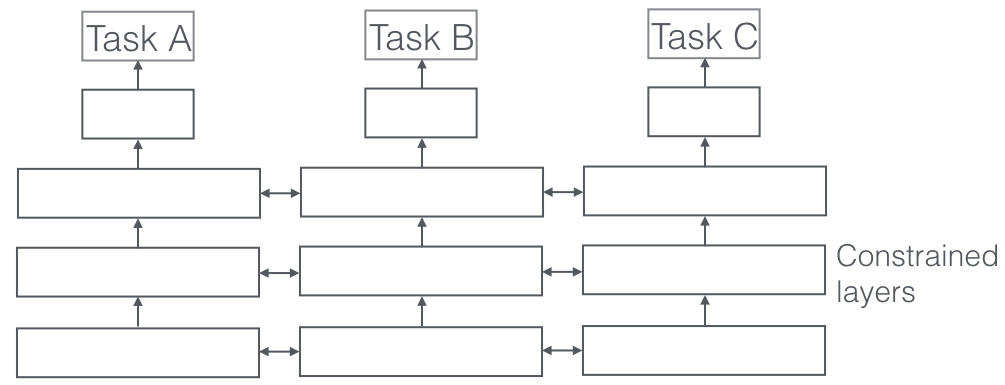
The soft sharing on the other hand, each task has their own model and parameters. The parameters between each task are encouraged to be similar with regulations and penalties.
Underlying MTL Mechanisms:
- Implicit Data Augumentation
- increase sample size
- different noise pattern among tasks smoothing the overall noise
- Attention Focusing
- Focus on features that really matters
- Providing relevence and irrlevence between features
- Eavesdropping
- Some task A interact with feature G better, which share information to task B to learn feature G better
- Representation Bias
- Helps with model generalization
- Regularization:
- Act as a “regularizer” by introducing an inductive bias -> reduce overfiting rate
Recent works MTL in Deep Learning
- Deep Relationship Networks

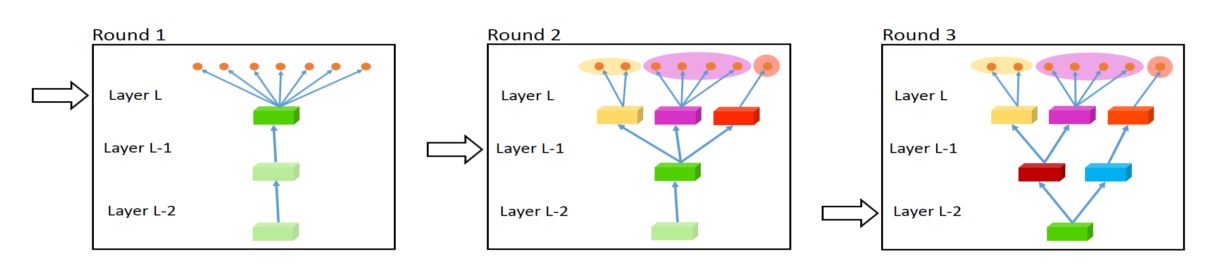
- Fully-Adaptive Feature Sharing
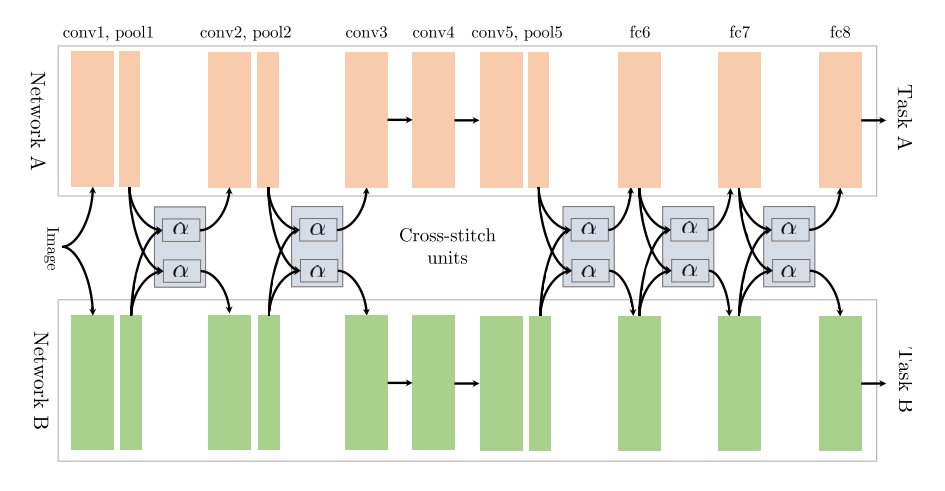
- Cross-stitch Networks
- Low Supervision
- A Joint Many Task Model
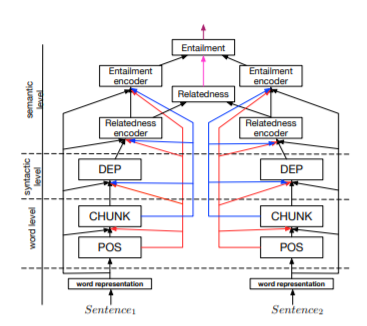
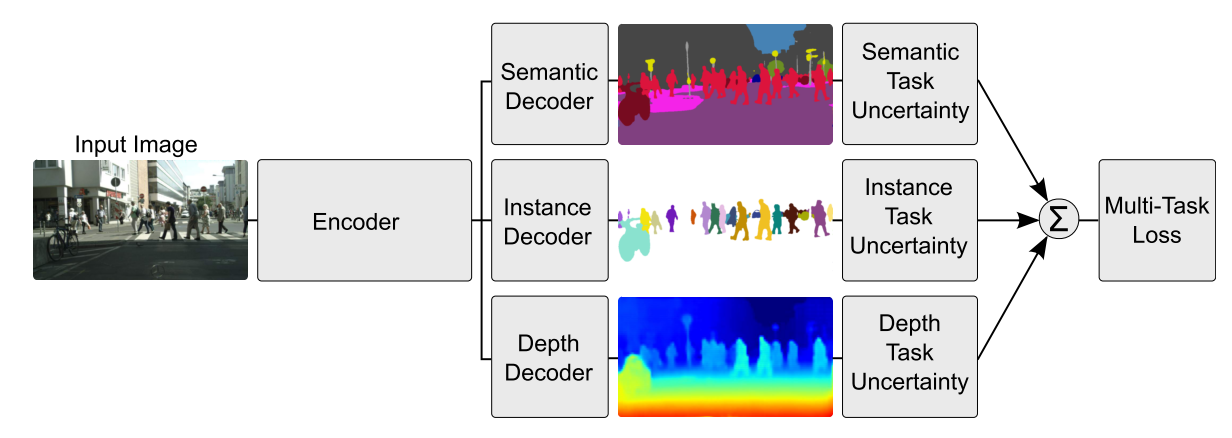
- Weighting Losses with Uncertainty
- Tensor Factorization for MTL

- Sluice Networks

MTL in non-neural models
- Block-sparse Regularization:
- Assumes: tasks used in multi-task learning are closely related
- enforce Lasso (L1 norm) to 0 out features
- Block-sparse regularization: \(l_1/l_q\) norms
- Learning task relationships:
- No assumption between tasks
- A constraint that enforces a clustering of tasks: penalizing both the norms of our task column vectors \(a_{·,1},\dots, a_{·,t}\) as well as their variance:
\(\Omega = ||\bar{a}||^2+\frac{\lambda}{T}\sum^{T}_{t=1}||a_{·,t}-\bar{a}||^2\) where \(\bar{a}=(\sum_{t=1}^{T}a_{.t})/T\) is the mean parameter vector. The penalty on the other hand forces all parameter \(a_{.t}\) to their mean \(\bar{a}\)
Auxiliary Tasks
MTL is a natural fit in situations where we are interested in obtaining predictions for multiple tasks at once. Such scenarios are common for instance in finance or economics forecasting, where we might want to predict the value of many possibly related indicators, or in bioinformatics where we might want to predict symptoms for multiple diseases simultaneously.
In scenarios such as drug discovery, where tens or hundreds of active compounds should be predicted, MTL accuracy increases continuously with the number of tasks
- Related task
- Using a related task as an auxiliary task for MTL
- uses tasks that predict different characteristics of the road as auxiliary tasks for predicting the steering direction in a self-driving car;
- use head pose estimation and facial attribute inference as auxiliary tasks for facial landmark detection;
- jointly learn query classification and web search;
- jointly predicts the class and the coordinates of an object in an image;
- jointly predict the phoneme duration and frequency profile for text-to-speech.
- Using a related task as an auxiliary task for MTL
- Adversarial
Often, labeled data for a related task is unavailable. In some circumstances, however, we have access to a task that is opposite of what we want to achieve.
- maximize the training error using a gradient reversal layer.
- Hints
learn features that might not be easy to learn just using the original task
- Focusing attention
focus attention on parts of the image that a network might normally ignore.
- Quantization smoothing
- Predicting inputs
- Using the future to predict the present
- Representation learning


